
意外にできる正規表現否定マッチングについて、
どう処理するるかのメモ書きです。
説明のために「?」を任意の1文字として表現しています。正規表現の「?」とは意味が違いますので注意してください(念のため、正規表現の方は半角の「?」で表現しておきます)。
否定先読みでまず試す
regexp
(?!.ing)....king
上の正規表現は『????kingにマッチするが、?ingが入るものは除外する(注:ここでの「?」は任意の1文字)』という意味です。
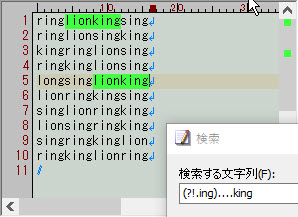
文字列を先頭から読んでいき、 "?ing" (注:ここでの「?」は任意の1文字)が続く場合はマッチング失敗として扱います。
これは「否定先読み」を使っています。
否定先読みとは、正規表現のマッチングした位置から先頭に向かって(左向きに処理が進むということ)、『「(?!」「)」で囲んだサブパターンがマッチしないこと』を検証する方法です。
この例では、????king の ???? の部分に ?ing が含まれるものは除外されます(注:ここでの「?」は任意の1文字)。
ポイント
先読みはマッチング位置は移動しません。次のマッチングも先頭から開始されます(戻読みも同様)。
「(?!.ing)」つまり、「?ing」にマッチングしない場合は、"????king" にはマッチングするのか検証してくれと言う意味になります(注:ここでの「?」は任意の1文字)。
regexp
^(?!ABCDE).*$
よくある上の例(先頭がABCDEで始まらないすべての行にマッチさせる)でテストすると以下のようにマッチします。
否定後読みでやってみる
regexp
....king(?<!sing)
上の正規表現は、
文字列を先頭から読んでいき "????ring"(注:ここでの「?」は任意の1文字) にマッチングする場合はマッチング成功です。
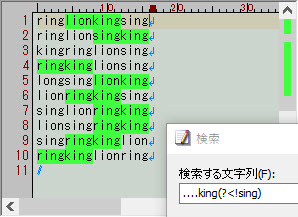
マッチング成功の場合に限り、マッチした文字列を最後尾から読んでいき、最後の4文字が "king" にマッチしたらマッチング失敗として扱います。「sing」のところを「.ing」とやってしまうと、これは「king」にマッチしてしまいますので、せっかく探した「....king」をすべて否定してしまうことになります。そのため省きたいパターンを特定して「sing」などとします。
この例では、まず"????king"を見つけ、その見つけた文字列の後ろが「sing」になっているものを排除します(注:ここでの「?」は任意の1文字)。
regexp
^.*(?<!fghij)$
よくある上の例(末尾がfghijで終わらないすべての行にマッチさせる)でテストすると以下のようにマッチします。
否定先読みと否定後読みは、正規表現に多少精通している人でも使いこなしていない人が多いと思いますので、積極的に使ってみるとコードが簡潔にまとまります。
{kind=link}